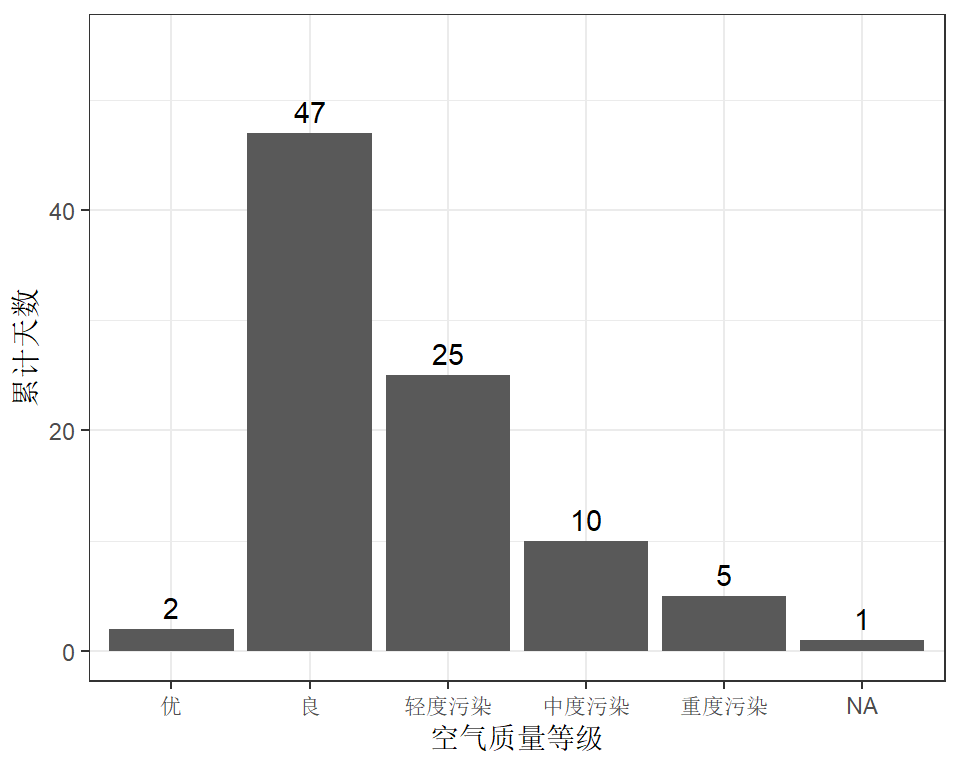
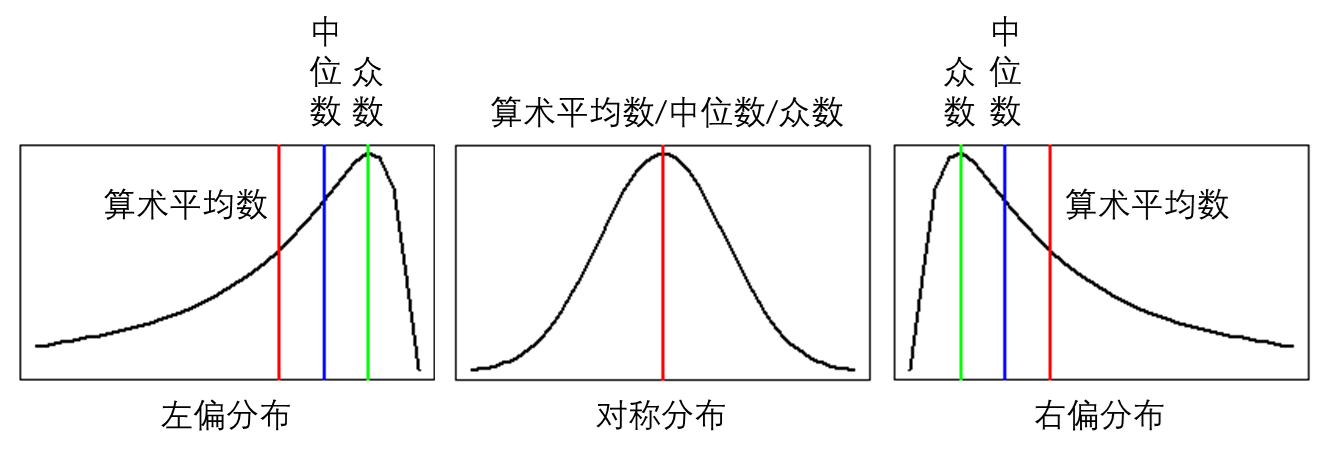
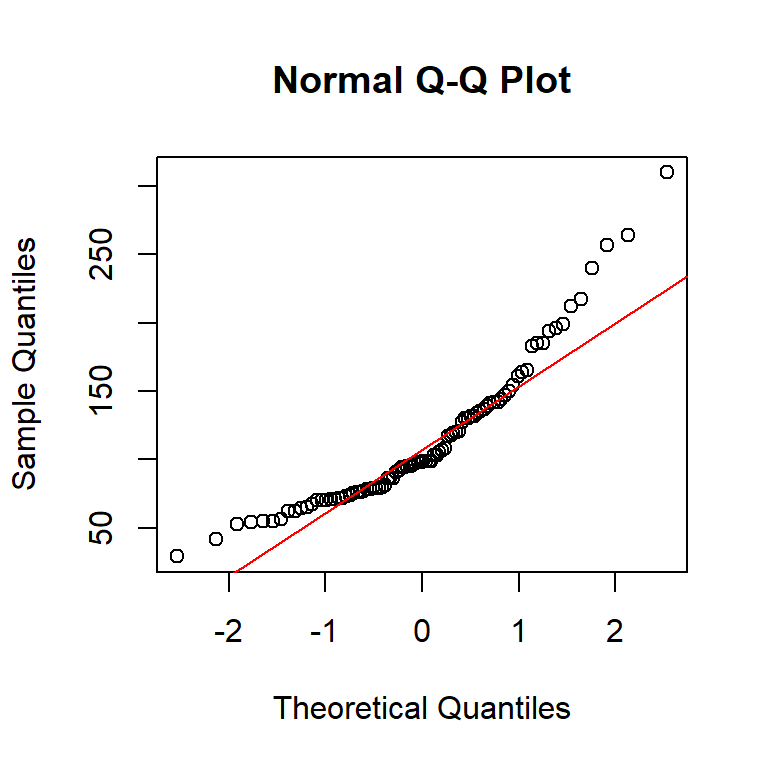
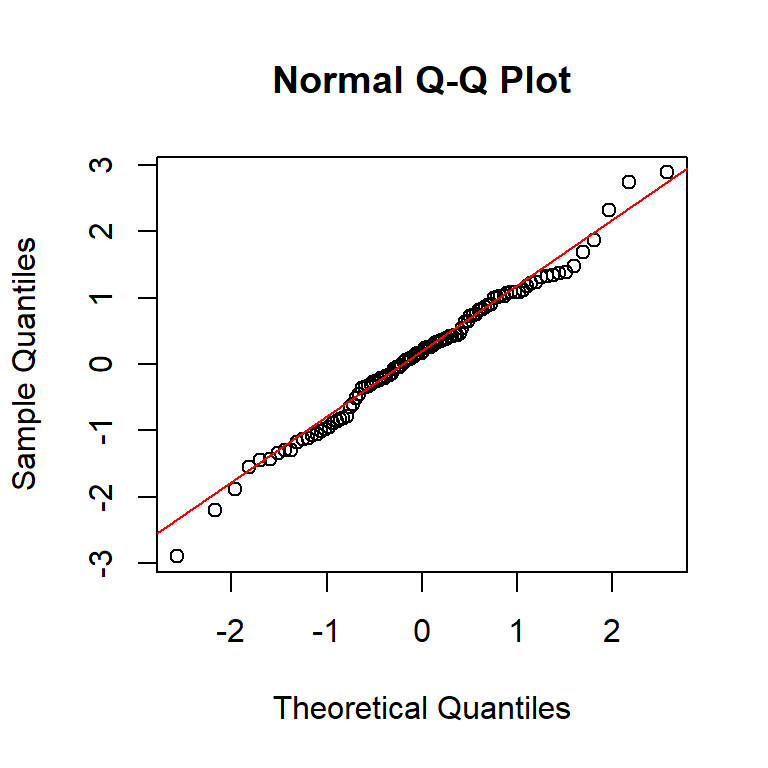
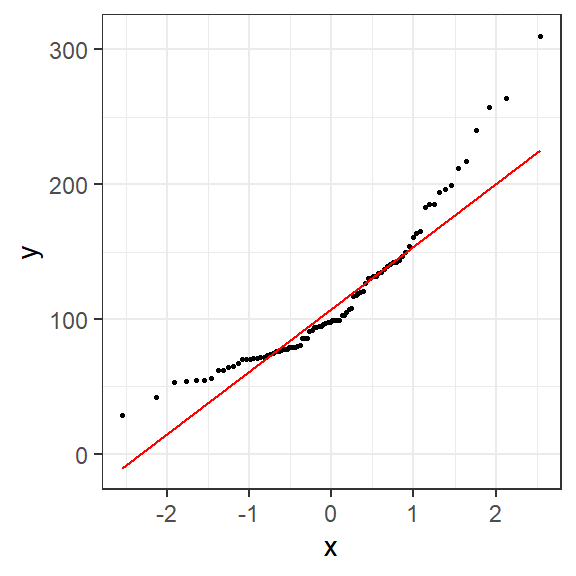
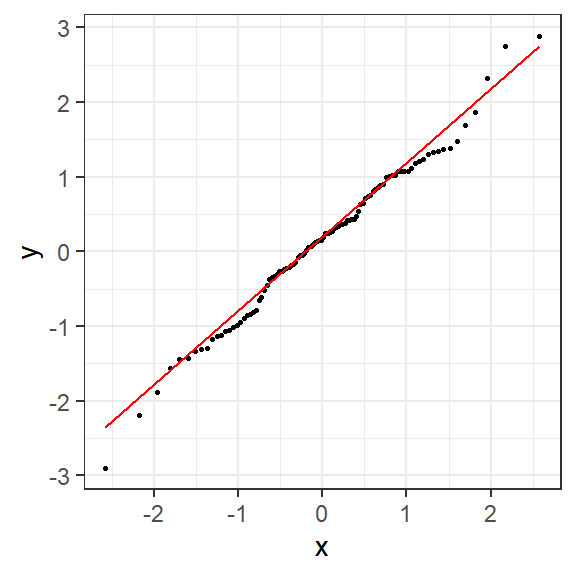
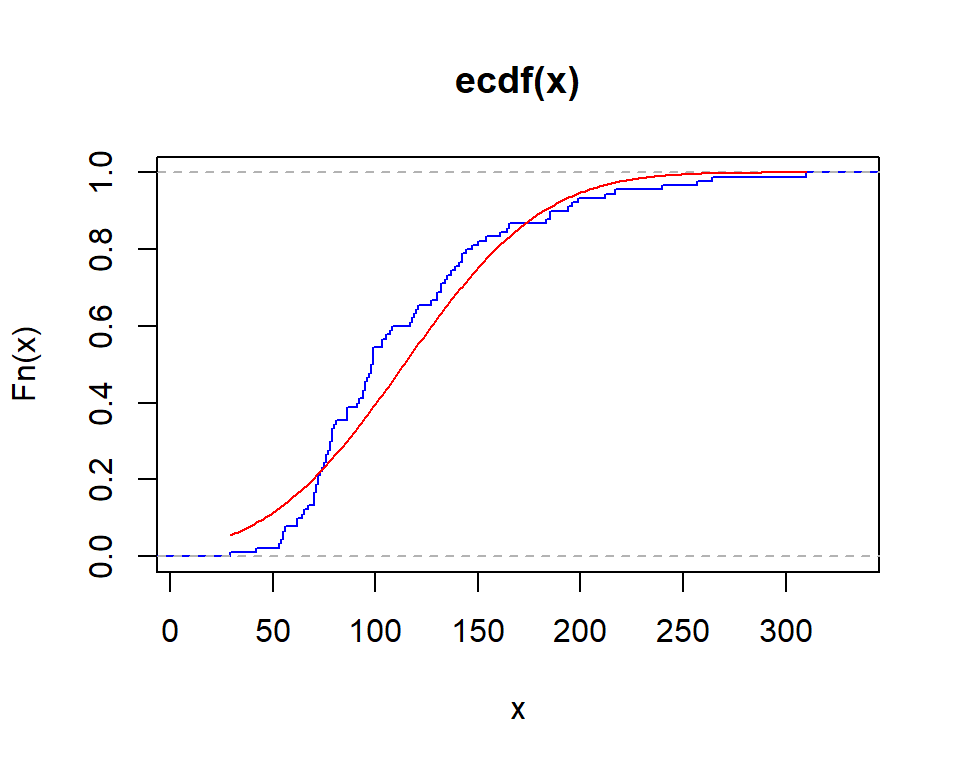
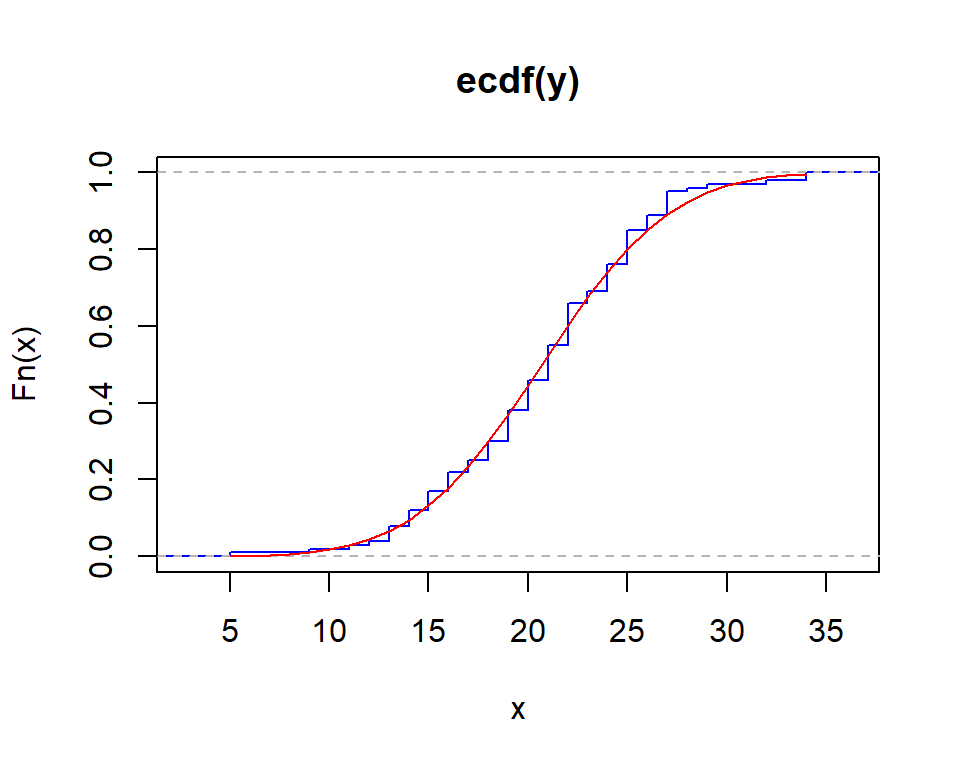
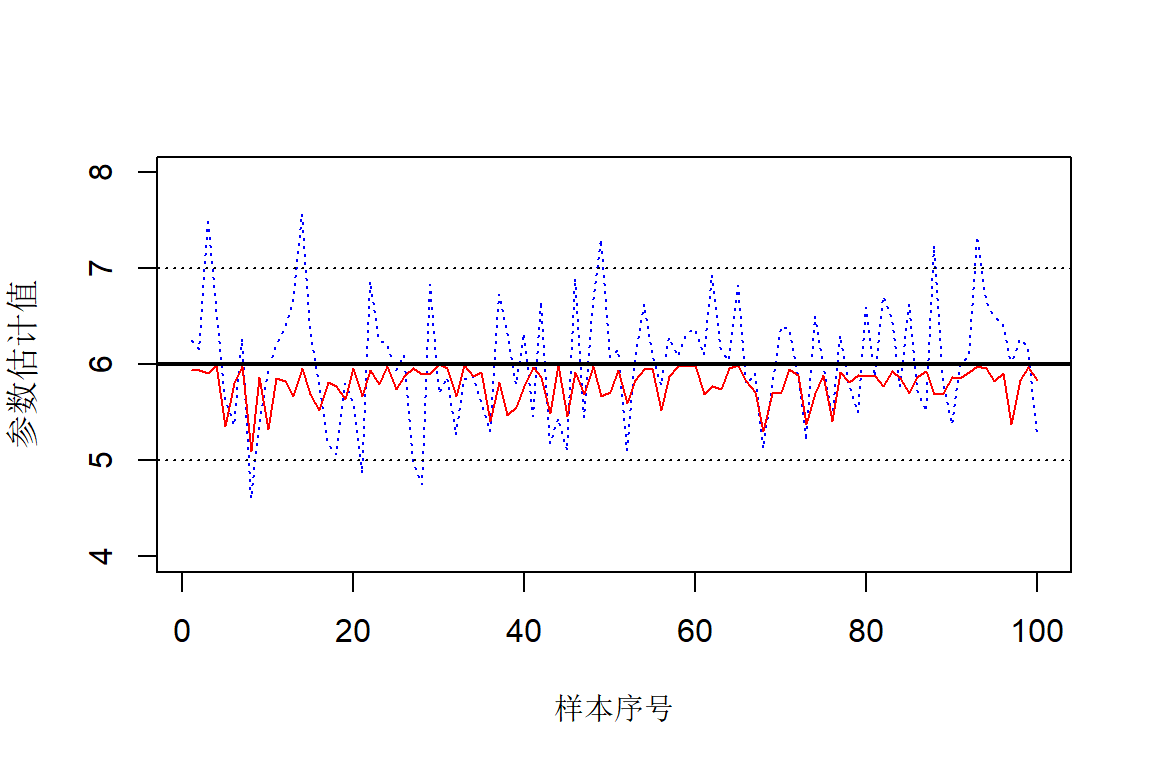
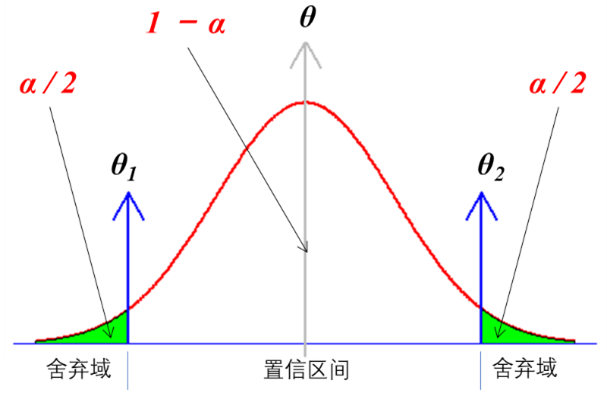
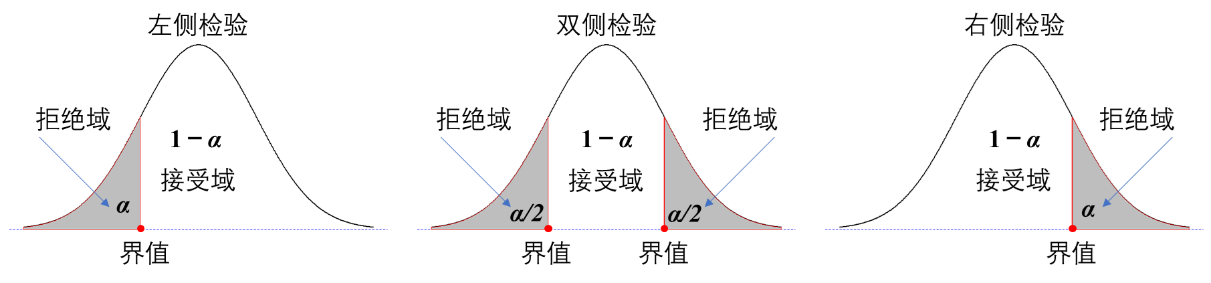
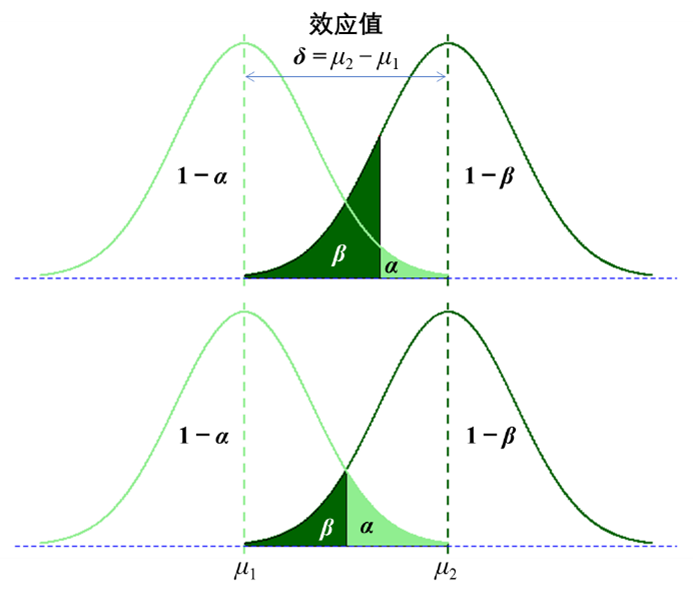
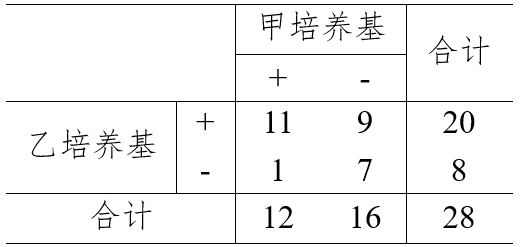
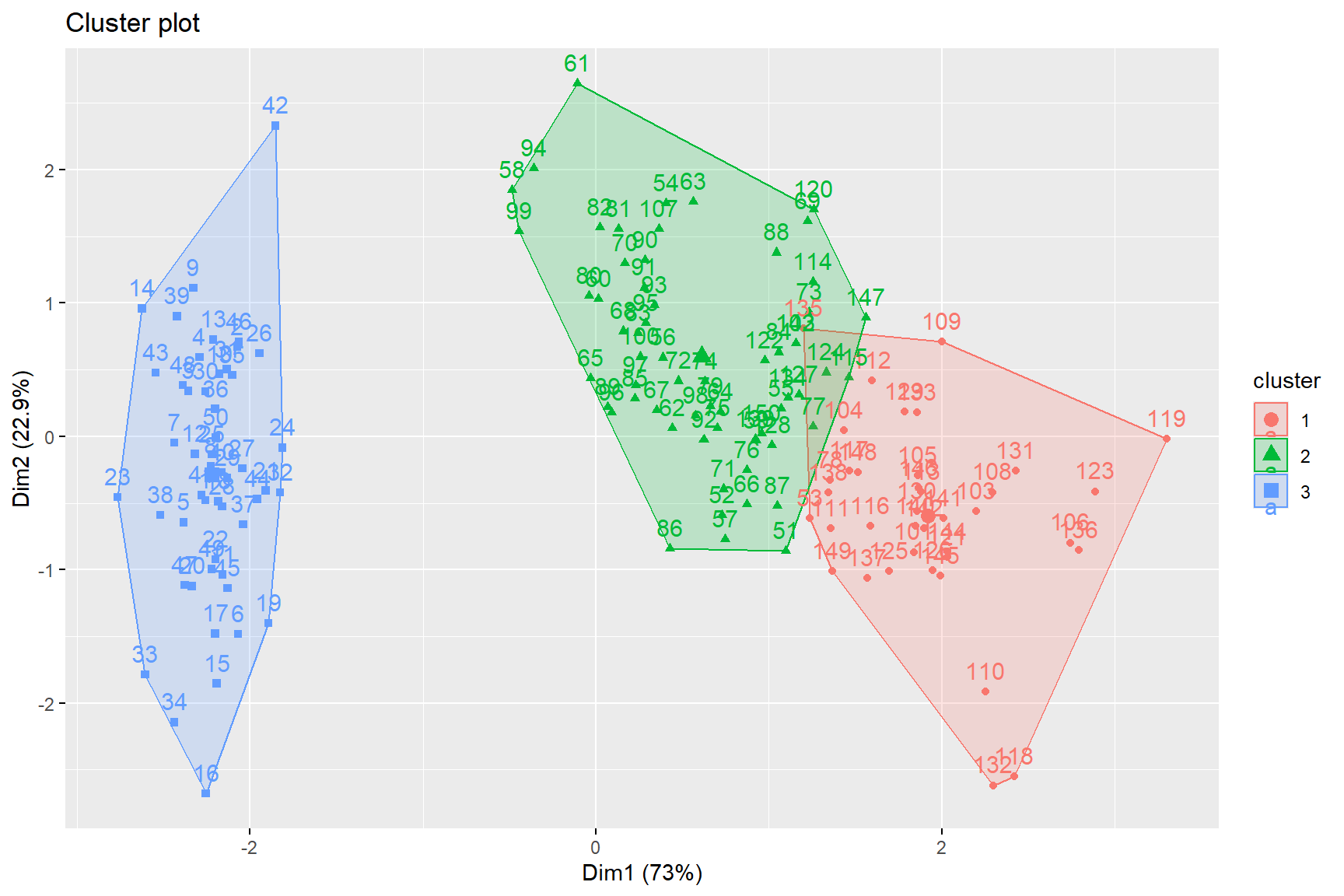
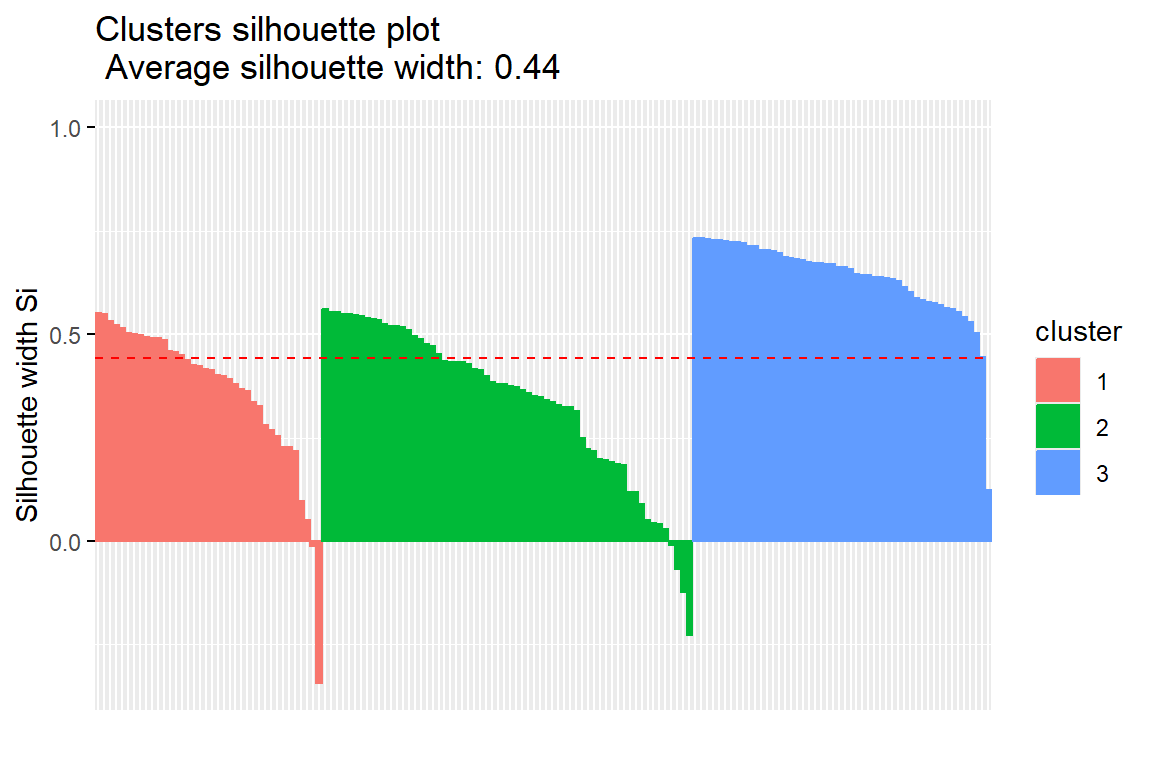
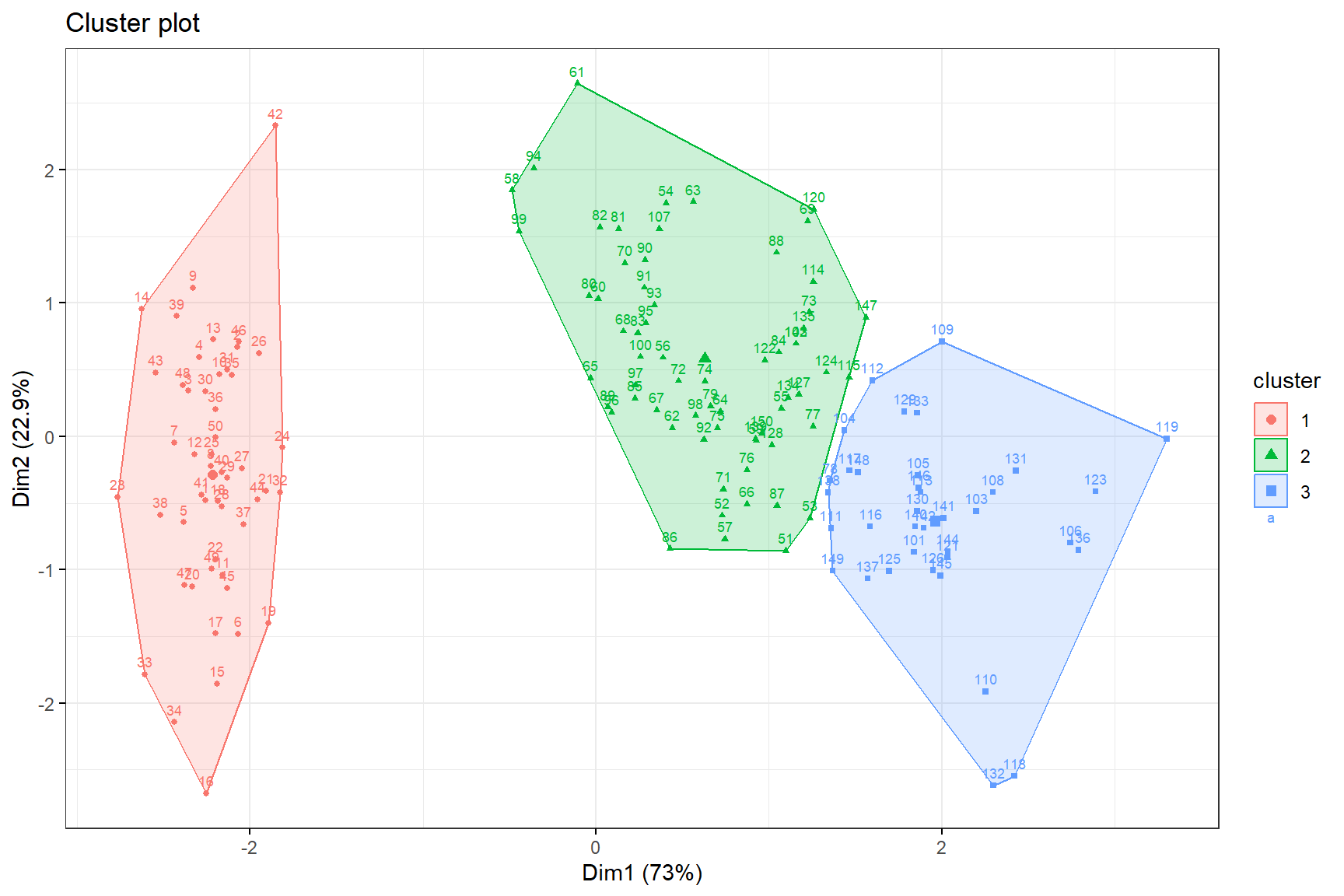
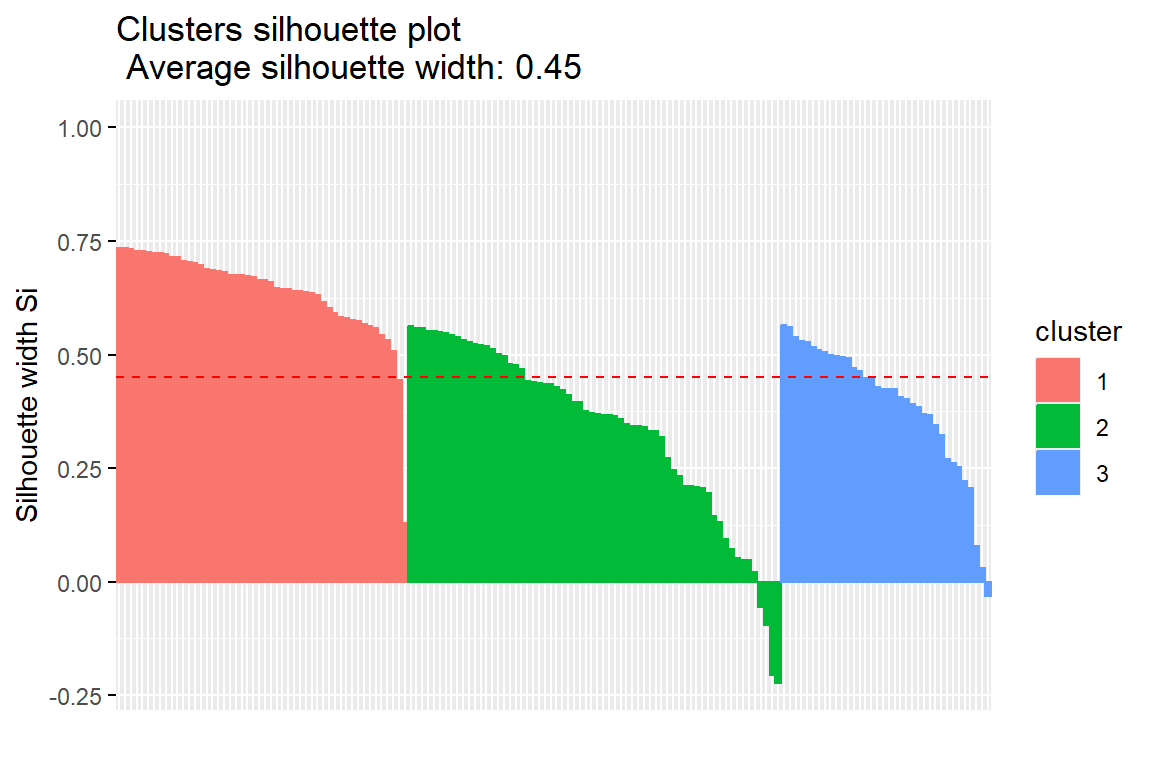
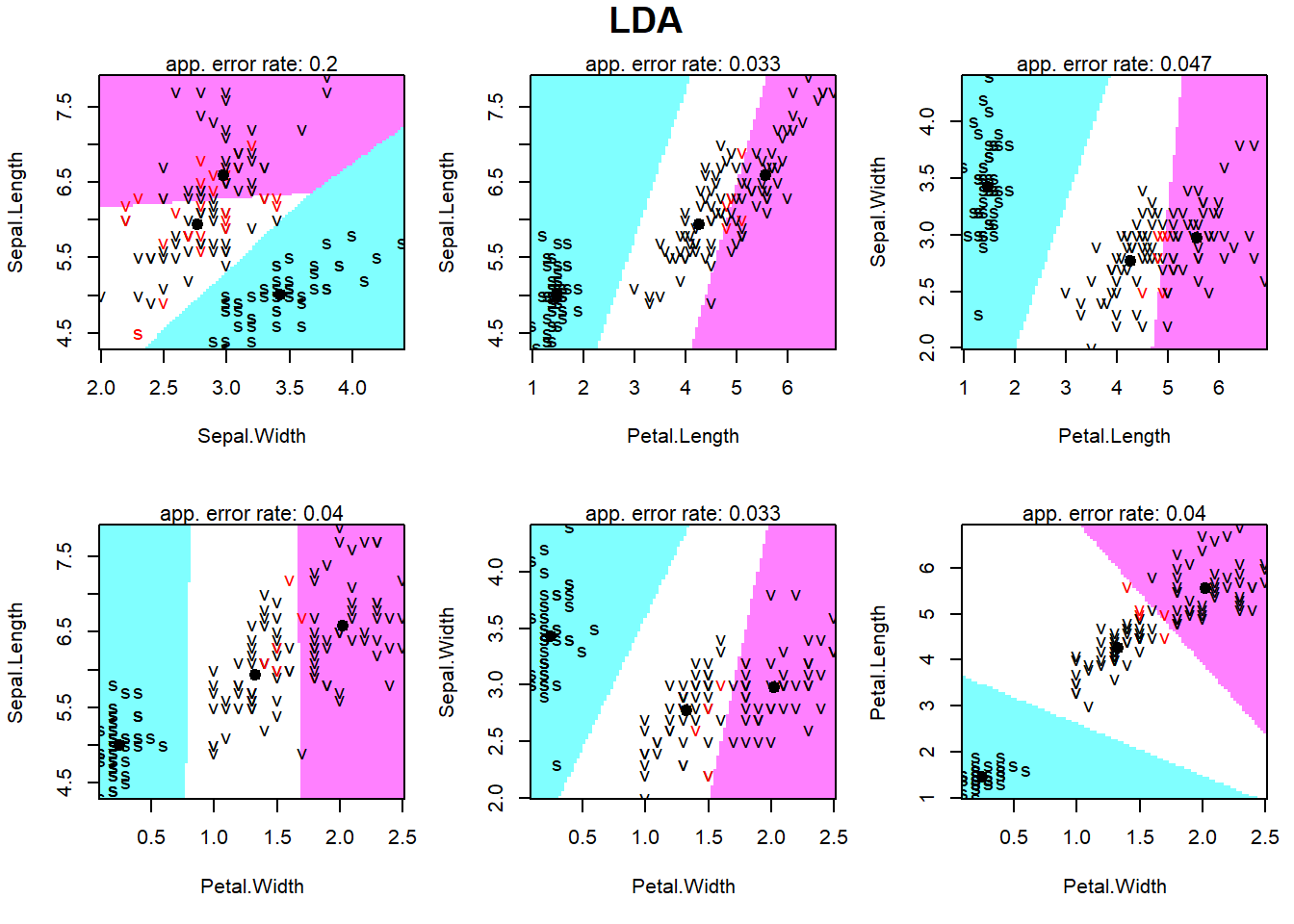
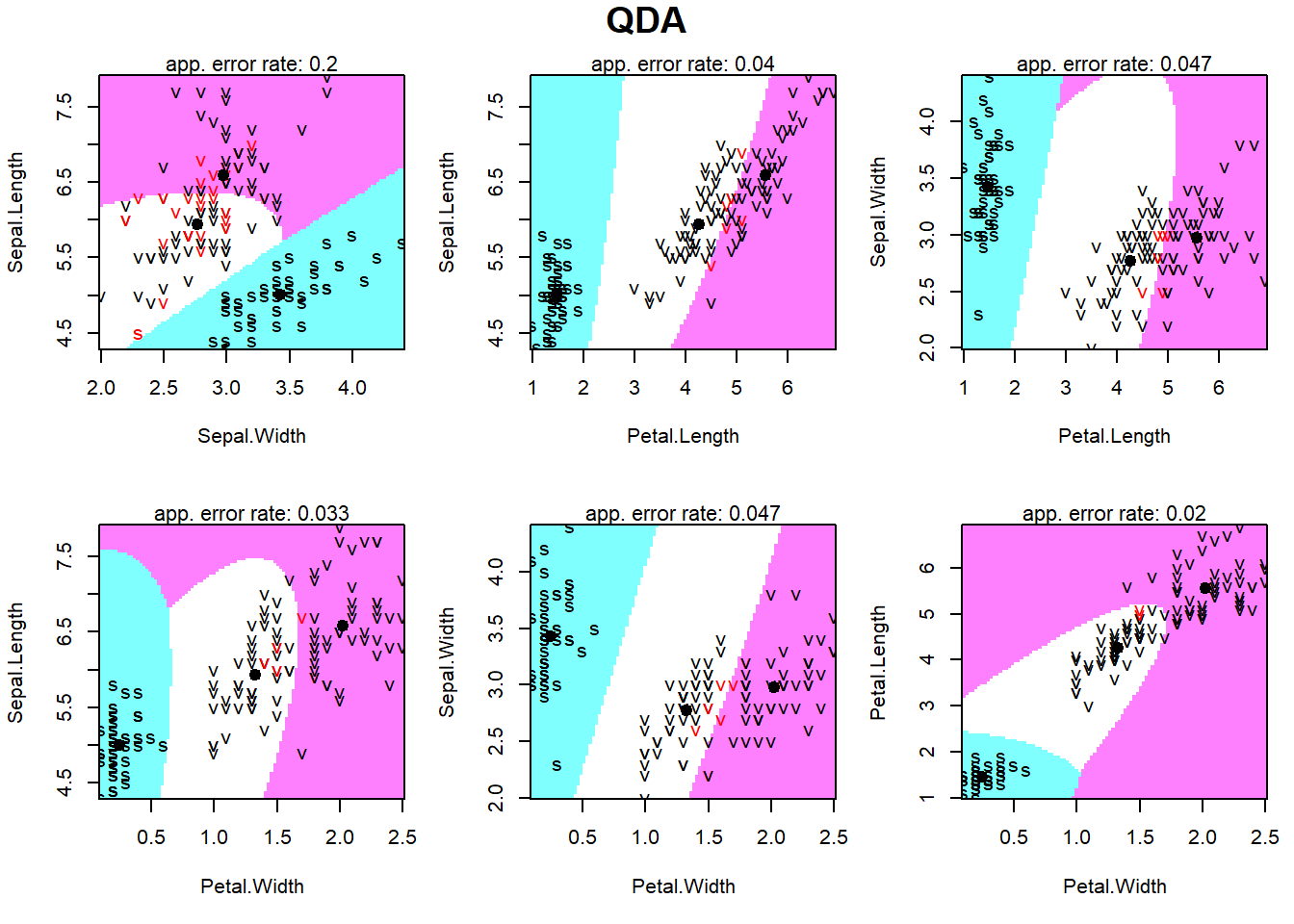
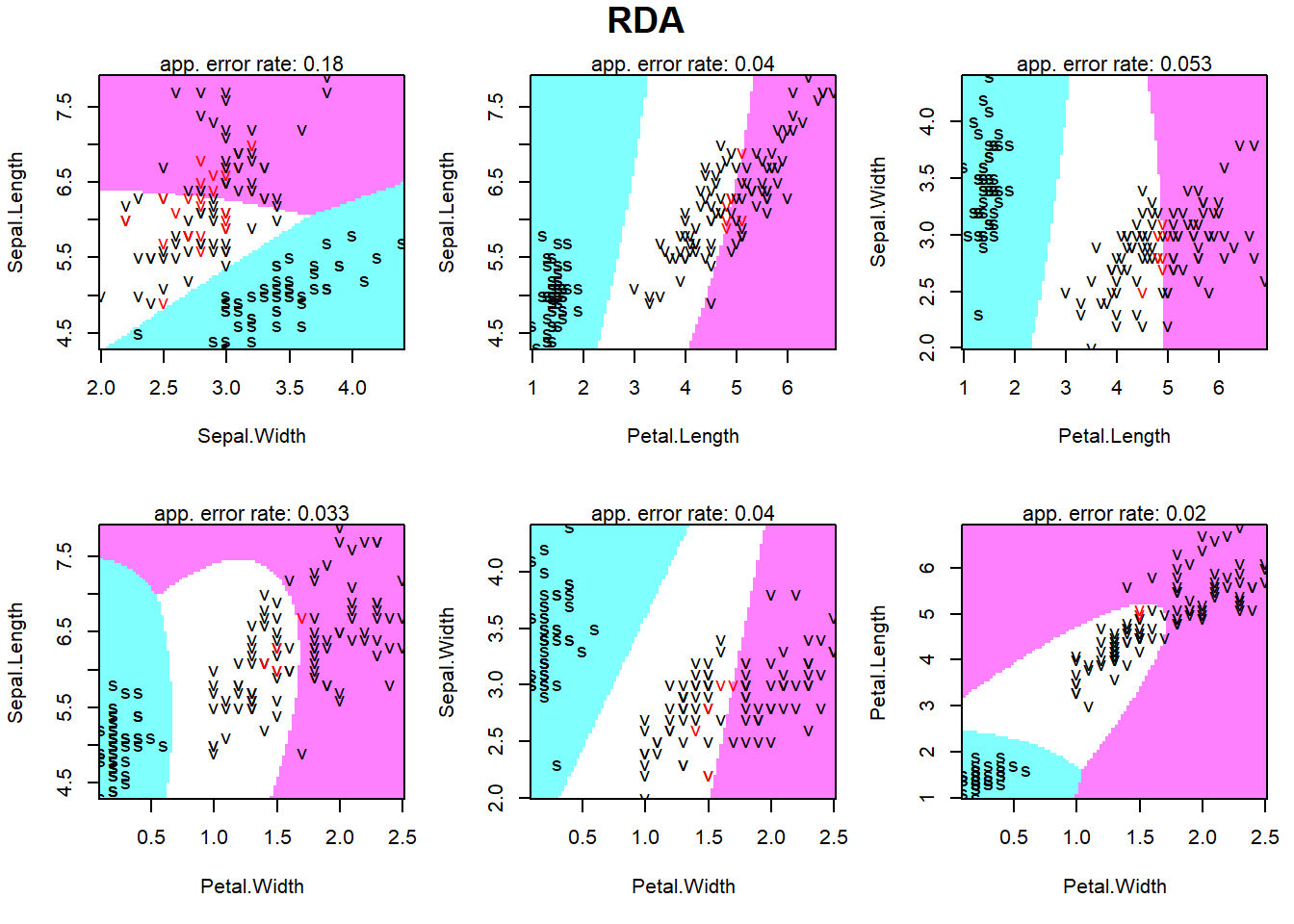
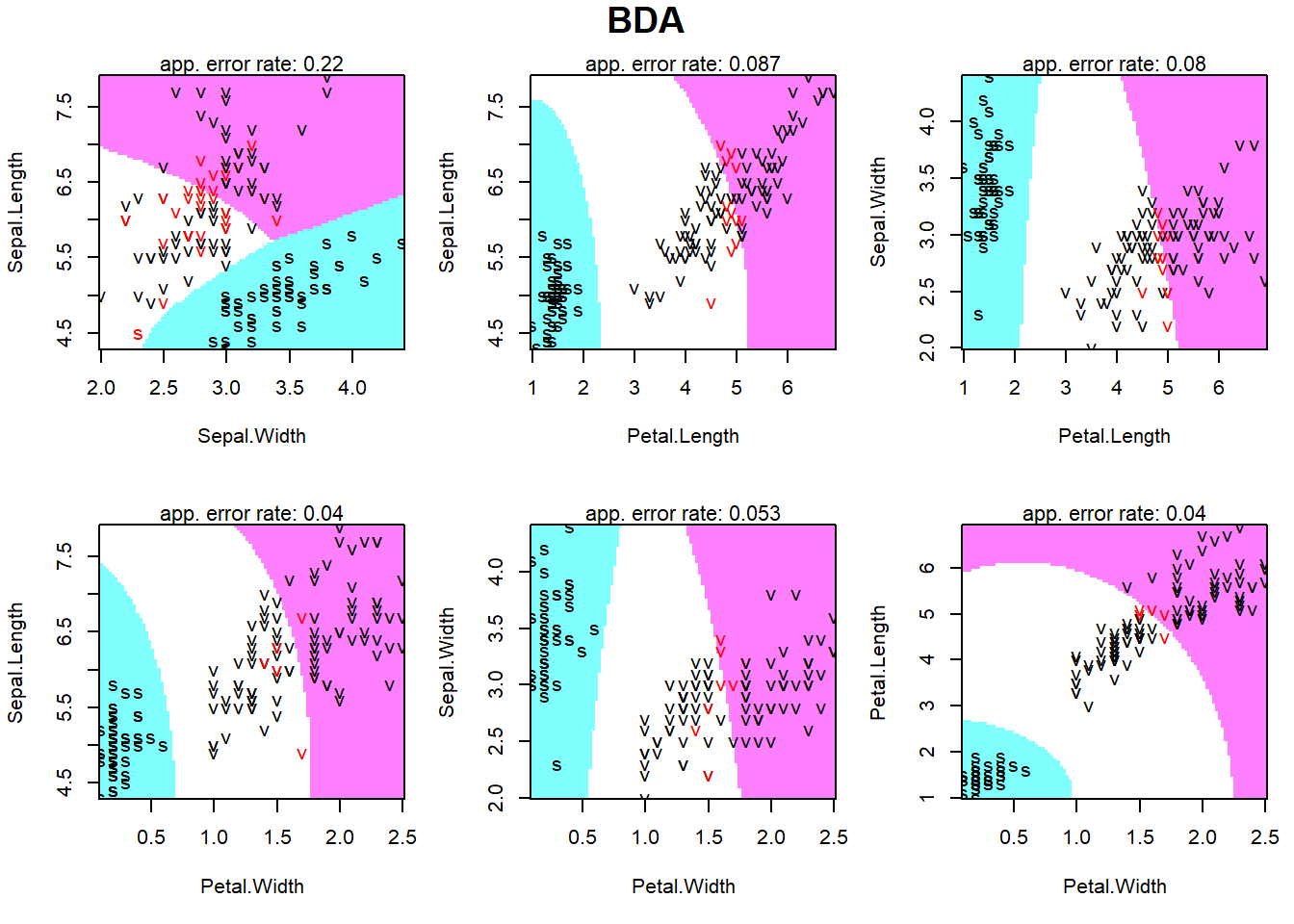
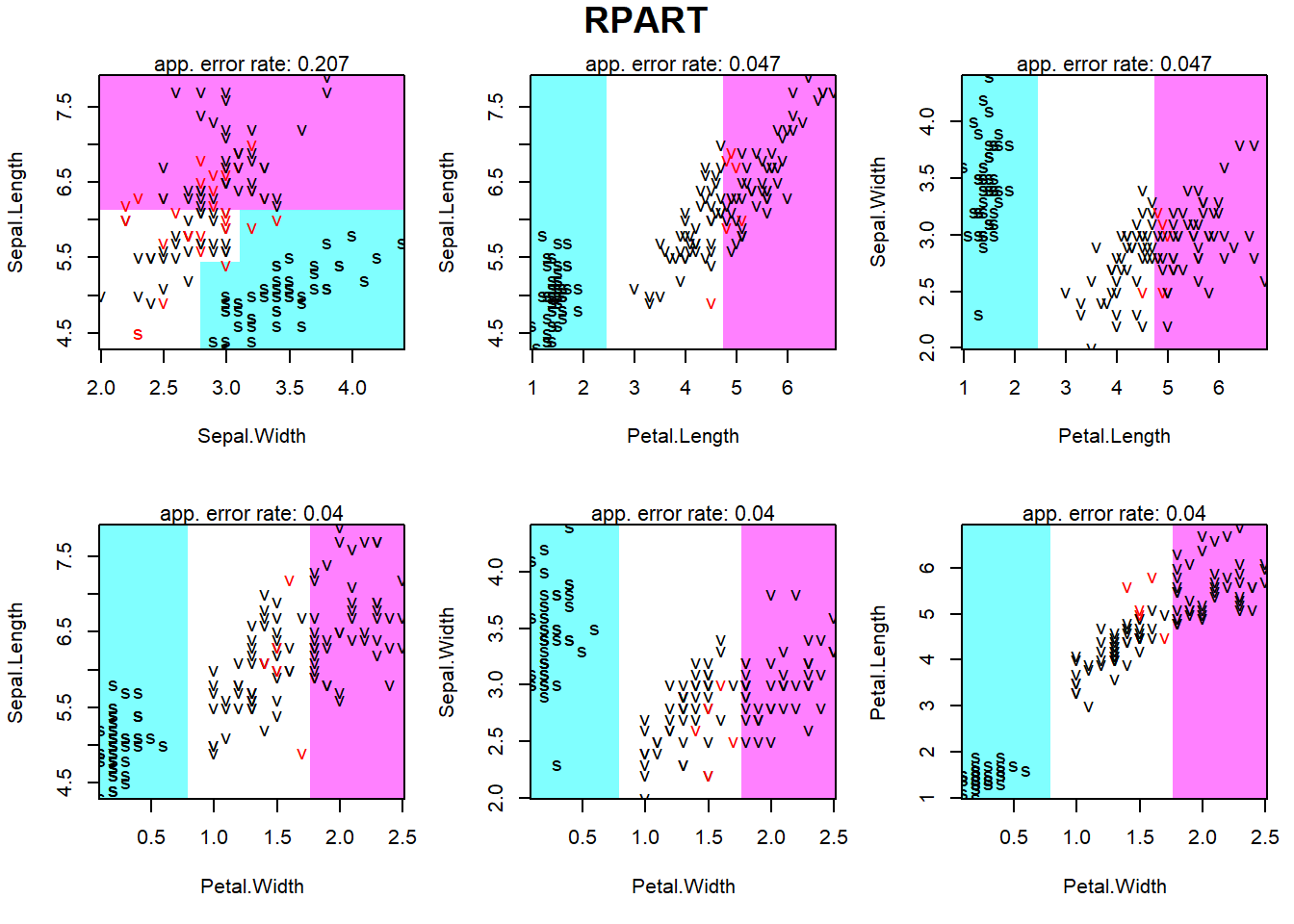
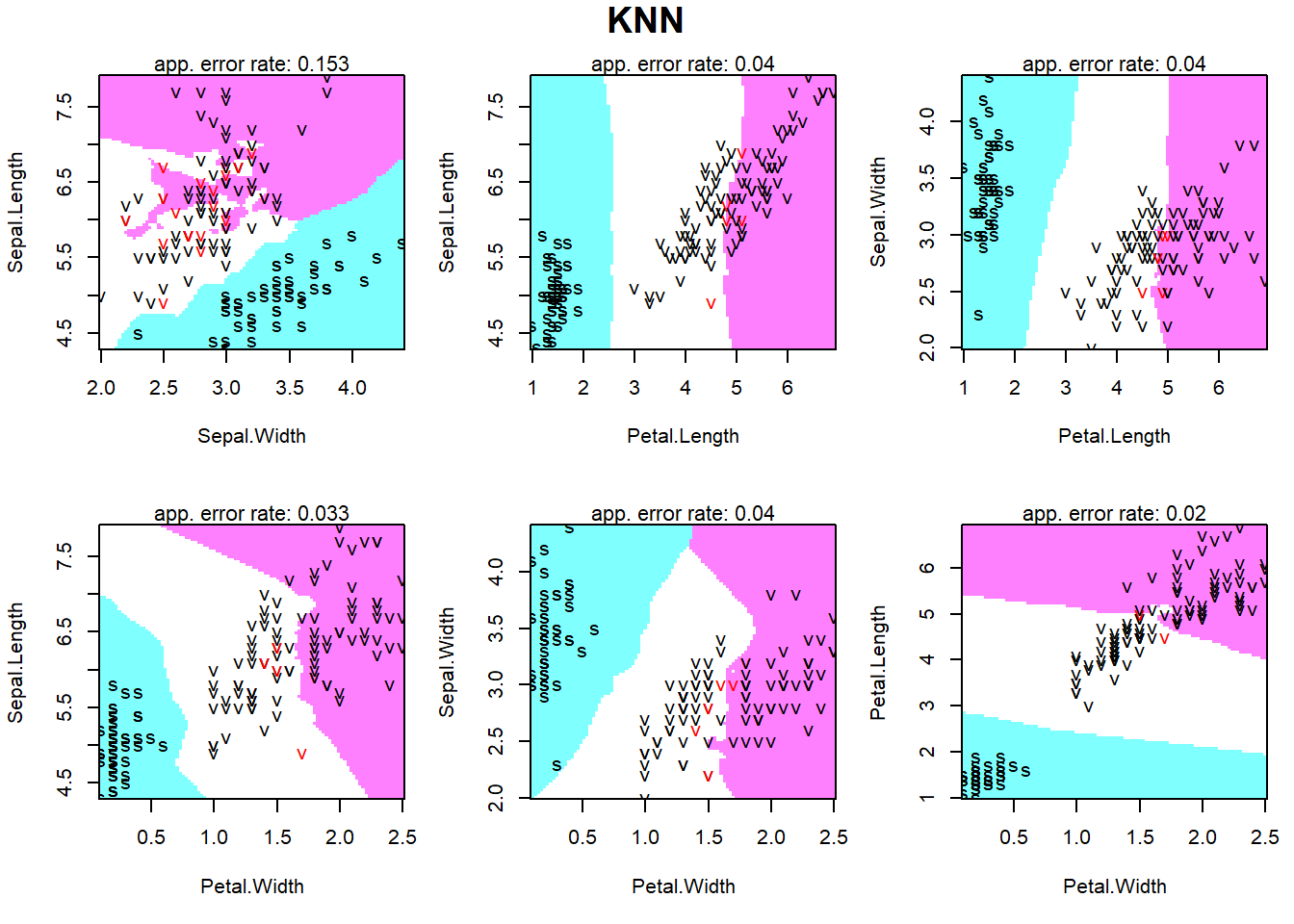
Ozone Solar.R Wind Temp
Min. : 1.00 Min. : 7.0 Min. : 1.700 Min. :56.00
1st Qu.: 18.00 1st Qu.:115.8 1st Qu.: 7.400 1st Qu.:72.00
Median : 31.50 Median :205.0 Median : 9.700 Median :79.00
Mean : 42.13 Mean :185.9 Mean : 9.958 Mean :77.88
3rd Qu.: 63.25 3rd Qu.:258.8 3rd Qu.:11.500 3rd Qu.:85.00
Max. :168.00 Max. :334.0 Max. :20.700 Max. :97.00
NA's :37 NA's :7
Month Day
Min. :5.000 Min. : 1.0
1st Qu.:6.000 1st Qu.: 8.0
Median :7.000 Median :16.0
Mean :6.993 Mean :15.8
3rd Qu.:8.000 3rd Qu.:23.0
Max. :9.000 Max. :31.0
# binom.test函数计算binom.test(x = np, n = n, conf.level =0.90)
Exact binomial test
data: np and n
number of successes = 3, number of trials = 63, p-value = 9.048e-15
alternative hypothesis: true probability of success is not equal to 0.5
90 percent confidence interval:
0.01310334 0.11849878
sample estimates:
probability of success
0.04761905
# prop.test函数计算prop.test(x = np, n = n, conf.level =0.90)
1-sample proportions test with continuity correction
data: np out of n, null probability 0.5
X-squared = 49.778, df = 1, p-value = 1.722e-12
alternative hypothesis: true p is not equal to 0.5
90 percent confidence interval:
0.01472307 0.12381063
sample estimates:
p
0.04761905
# 不使用连续性修正prop.test(x = np, n = n, conf.level =0.90, correct =FALSE)
1-sample proportions test without continuity correction
data: np out of n, null probability 0.5
X-squared = 51.571, df = 1, p-value = 6.904e-13
alternative hypothesis: true p is not equal to 0.5
90 percent confidence interval:
0.01918907 0.11330422
sample estimates:
p
0.04761905
x =c(3.1,3.2,3.3,2.9,3.5,3.4,2.5,4.3,3.0,3.4,2.9,3.6,3.2,3.0,2.7,3.5,2.9,3.3,3.3,3.1)t.test(x, alternative ="greater", mu =3, conf.level =0.95)
One Sample t-test
data: x
t = 2.4013, df = 19, p-value = 0.01337
alternative hypothesis: true mean is greater than 3
95 percent confidence interval:
3.057383 Inf
sample estimates:
mean of x
3.205
Welch Two Sample t-test
data: x and y
t = 4.1507, df = 11.003, p-value = 0.001614
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.0540609 0.1761058
sample estimates:
mean of x mean of y
0.1215833 0.0065000
F test to compare two variances
data: x and y
F = 0.79319, num df = 7, denom df = 6, p-value = 0.7608
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.1392675 4.0600387
sample estimates:
ratio of variances
0.7931937
n =210x =23p0 =0.08prop.test(x, n, p = p0, alternative ="greater", conf.level =0.95)
1-sample proportions test with continuity correction
data: x out of n, null probability p0
X-squared = 2.1021, df = 1, p-value = 0.07355
alternative hypothesis: true p is greater than 0.08
95 percent confidence interval:
0.07690104 1.00000000
sample estimates:
p
0.1095238
采用`binom.test()检验:
binom.test(x, n, p = p0, alternative ="greater", conf.level =0.95)
Exact binomial test
data: x and n
number of successes = 23, number of trials = 210, p-value = 0.07812
alternative hypothesis: true probability of success is greater than 0.08
95 percent confidence interval:
0.07602032 1.00000000
sample estimates:
probability of success
0.1095238
2-sample test for equality of proportions with continuity correction
data: x out of n
X-squared = 30.22, df = 1, p-value = 3.858e-08
alternative hypothesis: two.sided
95 percent confidence interval:
-0.17711583 -0.08305896
sample estimates:
prop 1 prop 2
0.04213483 0.17222222
Warning in chisq.test(mt): Chi-squared approximation may be incorrect
Pearson's Chi-squared test with Yates' continuity correction
data: mt
X-squared = 3.444, df = 1, p-value = 0.06348
检验结果发现接受H0,但p接近检验水准\alpha,改用Fisher精确检验:
fisher.test(mt)
Fisher's Exact Test for Count Data
data: mt
p-value = 0.04204
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.9160508 73.9370368
sample estimates:
odds ratio
6.266107
aov(formula, data =NULL, projections =FALSE, qr =TRUE,contrasts =NULL, ...)
formula是一个用公式指定的模型,如”y ~ x”,“y ~ a + b + c”,“y ~ a + b + a:b”等。其中常用的符号及其意义如 表 4.3 所示。data是包含所有变量的数据框。projections为逻辑值,指定是否返回投影。qr为逻辑值,指定是否返回QR分解结果。contrasts是用于公式中某些因素的对比列表。…是传递给线性模型lm()函数的其他参数。
表 4.3: R中formula中常用的符号及其意义
符号
含义
~
左边为因变量,右边为自变量。例如通过a、b和c预测y,代码为y ~ a + b + c
+
分隔自变量
:
表示自变量的交互项。例如通过a、b及其交互项预测y,代码为y ~ a + b + a:b
*
表示所有可能交互项的简洁方式。例如y ~ a * b * c等价于y ~ a + b + c + a:b + b:c + c:a
^
表示交互项达到某个次数。例如y ~ (a + b + c)^2等价于y ~ (a + b + c) * (a + b + c)
.
点号,表示包含除因变量外的所有变量。例如数据包含变量y、a、b和c,代码y ~ . 等价于y ~ a + b + c
-
表示从等式中移除某个变量。例如y ~ (a + b + c)^2 – a:b等价于y ~ a + b + c + b:c + c:a
%in%
表示其左侧项嵌套如右侧项中。如y ~ a + b %in% a等价于y ~ a + a:b
-1或+0
删除截距项。例如y ~ a - 1或y ~ a + 0,强制直线方程通过原点
函数I()
避免公式中算术运算符和符号运算符产生混淆。例如y ~ a + (b + c)^2等价于y ~ a + b + c + b:c;相反, y ~ a + I((b + c)^2)等价于y ~ a + h,h是b与c之和的平方
函数引用
可以在表达式中用的数学函数。例如log(y) ~ a + b + c表示通过a、b和c来预测log(y)
Pairwise comparisons using t tests with pooled SD
data: conc and season
春 冬 秋
冬 0.00044 - -
秋 0.00096 1.00000 -
夏 1.00000 0.01579 0.03223
P value adjustment method: bonferroni
# 计算pearseon相关系数并进行检验cor.test(x, y, method ="pearson")
Pearson's product-moment correlation
data: x and y
t = 3.5134, df = 7, p-value = 0.009814
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.2869339 0.9558528
sample estimates:
cor
0.7988311
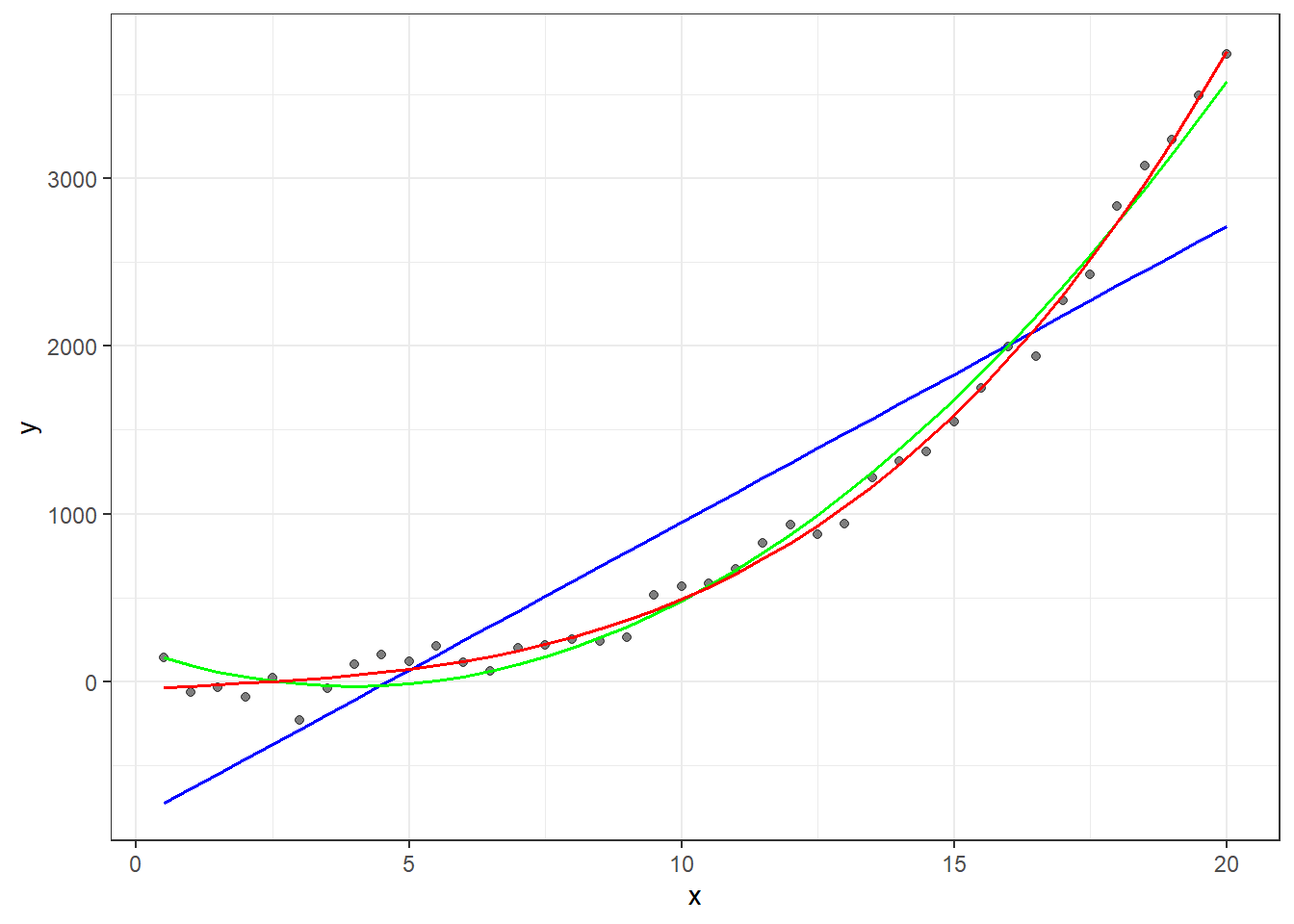
Call:
lm(formula = y ~ poly(x, 2), data = df)
Coefficients:
(Intercept) poly(x, 2)1 poly(x, 2)2
993.5 6445.6 2644.3
ASSESSMENT OF THE LINEAR MODEL ASSUMPTIONS
USING THE GLOBAL TEST ON 4 DEGREES-OF-FREEDOM:
Level of Significance = 0.05
Call:
gvlma(x = fm2)
Value p-value Decision
Global Stat 21.41383 2.621e-04 Assumptions NOT satisfied!
Skewness 0.28416 5.940e-01 Assumptions acceptable.
Kurtosis 1.38066 2.400e-01 Assumptions acceptable.
Link Function 19.72332 8.950e-06 Assumptions NOT satisfied!
Heteroscedasticity 0.02569 8.727e-01 Assumptions acceptable.
gvlma(fm3)
Call:
lm(formula = y ~ poly(x, 3), data = df)
Coefficients:
(Intercept) poly(x, 3)1 poly(x, 3)2 poly(x, 3)3
993.5 6445.6 2644.3 490.9
ASSESSMENT OF THE LINEAR MODEL ASSUMPTIONS
USING THE GLOBAL TEST ON 4 DEGREES-OF-FREEDOM:
Level of Significance = 0.05
Call:
gvlma(x = fm3)
Value p-value Decision
Global Stat 5.3380 0.2543 Assumptions acceptable.
Skewness 1.3014 0.2540 Assumptions acceptable.
Kurtosis 0.2838 0.5942 Assumptions acceptable.
Link Function 1.6340 0.2012 Assumptions acceptable.
Heteroscedasticity 2.1188 0.1455 Assumptions acceptable.
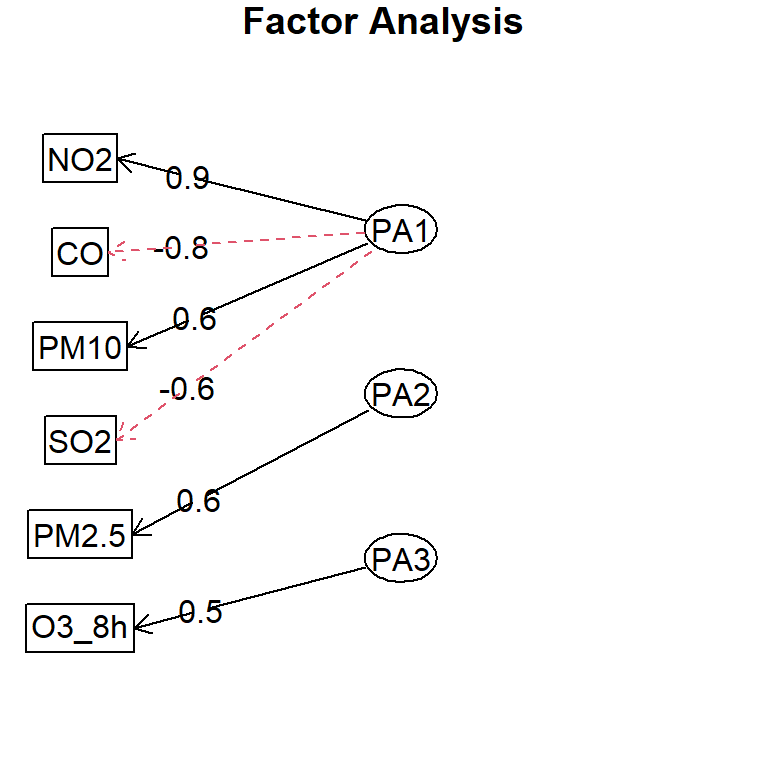
fa_aqi =fa(cor(df), nfactors =3, fm ="pa", rotate ="varimax")fa_aqi
Factor Analysis using method = pa
Call: fa(r = cor(df), nfactors = 3, rotate = "varimax", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 PA3 h2 u2 com
PM2.5 -0.06 0.63 0.03 0.40 0.60 1.0
PM10 0.61 0.47 -0.02 0.60 0.40 1.9
CO -0.77 0.29 0.07 0.67 0.33 1.3
NO2 0.93 0.07 0.04 0.88 0.12 1.0
SO2 -0.61 0.01 -0.47 0.59 0.41 1.9
O3_8h -0.01 0.02 0.47 0.22 0.78 1.0
PA1 PA2 PA3
SS loadings 2.21 0.71 0.45
Proportion Var 0.37 0.12 0.07
Cumulative Var 0.37 0.49 0.56
Proportion Explained 0.66 0.21 0.13
Cumulative Proportion 0.66 0.87 1.00
Mean item complexity = 1.3
Test of the hypothesis that 3 factors are sufficient.
df null model = 15 with the objective function = 1.83
df of the model are 0 and the objective function was 0
The root mean square of the residuals (RMSR) is 0
The df corrected root mean square of the residuals is NA
Fit based upon off diagonal values = 1
Measures of factor score adequacy
PA1 PA2 PA3
Correlation of (regression) scores with factors 0.96 0.77 0.67
Multiple R square of scores with factors 0.91 0.60 0.44
Minimum correlation of possible factor scores 0.82 0.20 -0.11